引入BDK树
引入一
mysql的复合索引问题
https://blog.csdn.net/wanyu_123/article/details/122347708
https://www.cnblogs.com/lijiaman/p/14364171.html
复合索引有最左匹配问题,有没有一种索引结构能解决最左匹配的问题?只需要有一个索引(a,b,c),我们可以查询a,也可以查询b,也可以查询c
引入二
在es的文档中:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/documents-indices.html
An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data. By default, Elasticsearch indexes all data in every field and each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees. The ability to use the per-field data structures to assemble and return search results is what makes Elasticsearch so fast.
注意上面的geo fields are stored in BKD trees也就是说地理坐标存储在bkd树中
概念
KD树(K-Dimensional Tree)
https://en.wikipedia.org/wiki/K-d_tree
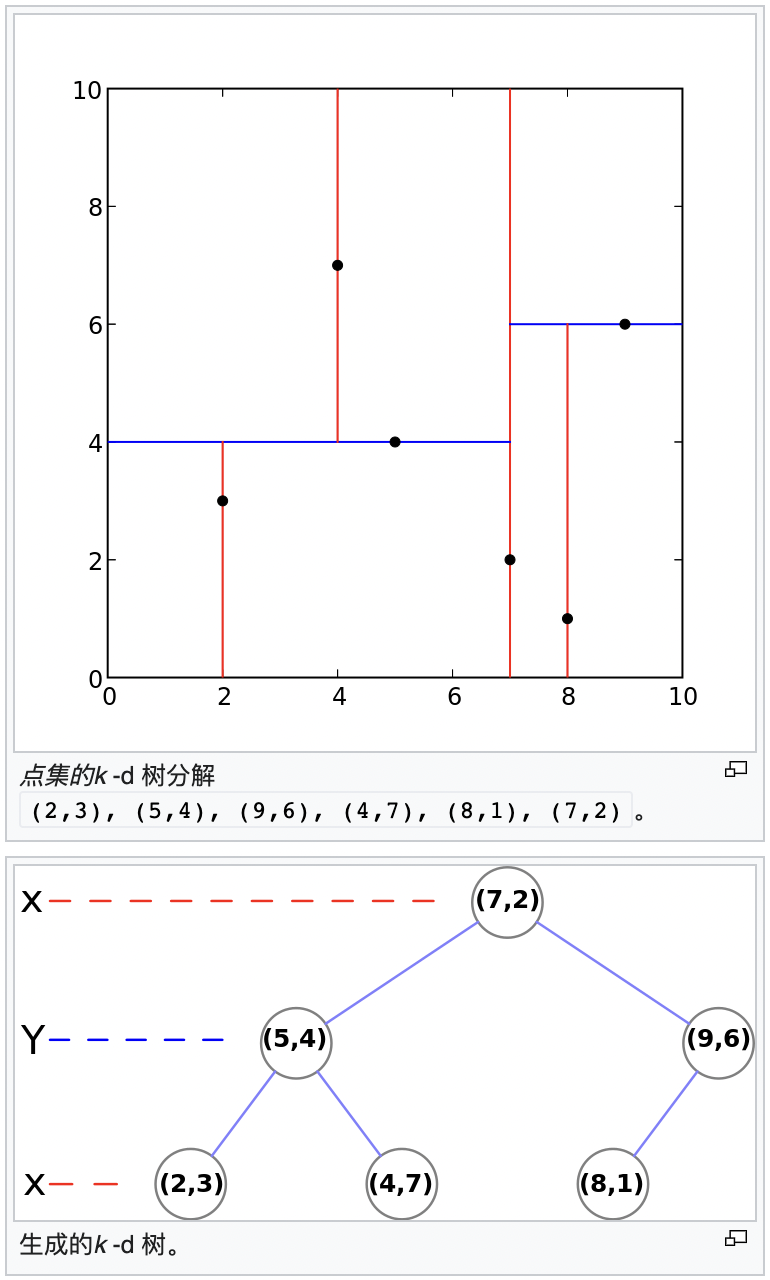
优点:支持多维查询
缺点:只适合静态数据的查询,非平衡树,插入元素是效率低并且插入后结构改变无法自平衡(参考二叉树退化为链表),属于内存数据结构
KDB树(K-Dimension Balanced Tree)
https://en.wikipedia.org/wiki/K-D-B-tree
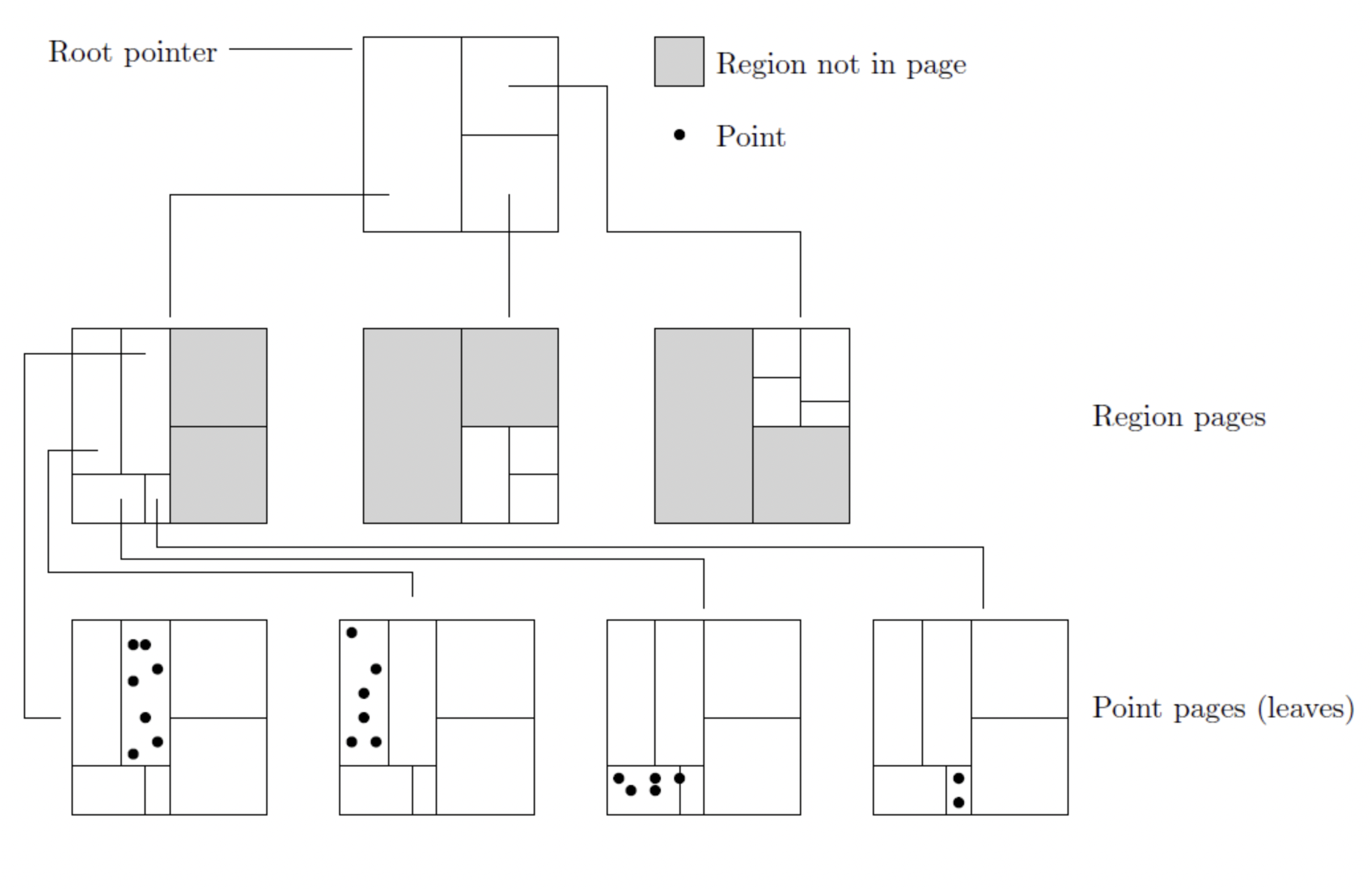
KD树的外存版本,直接将二叉树修改为b+树
优点:海量多维静态数据查询速度快
缺点:更新时速度慢
BKD树(Block K-Dimension Balanced Tree)
BKD树论文:https://users.cs.duke.edu/~pankaj/publications/papers/bkd-sstd.pdf
开源代码实现:https://github.com/digidem/bkd-tree/blob/master/data.md
BKD树实现原理
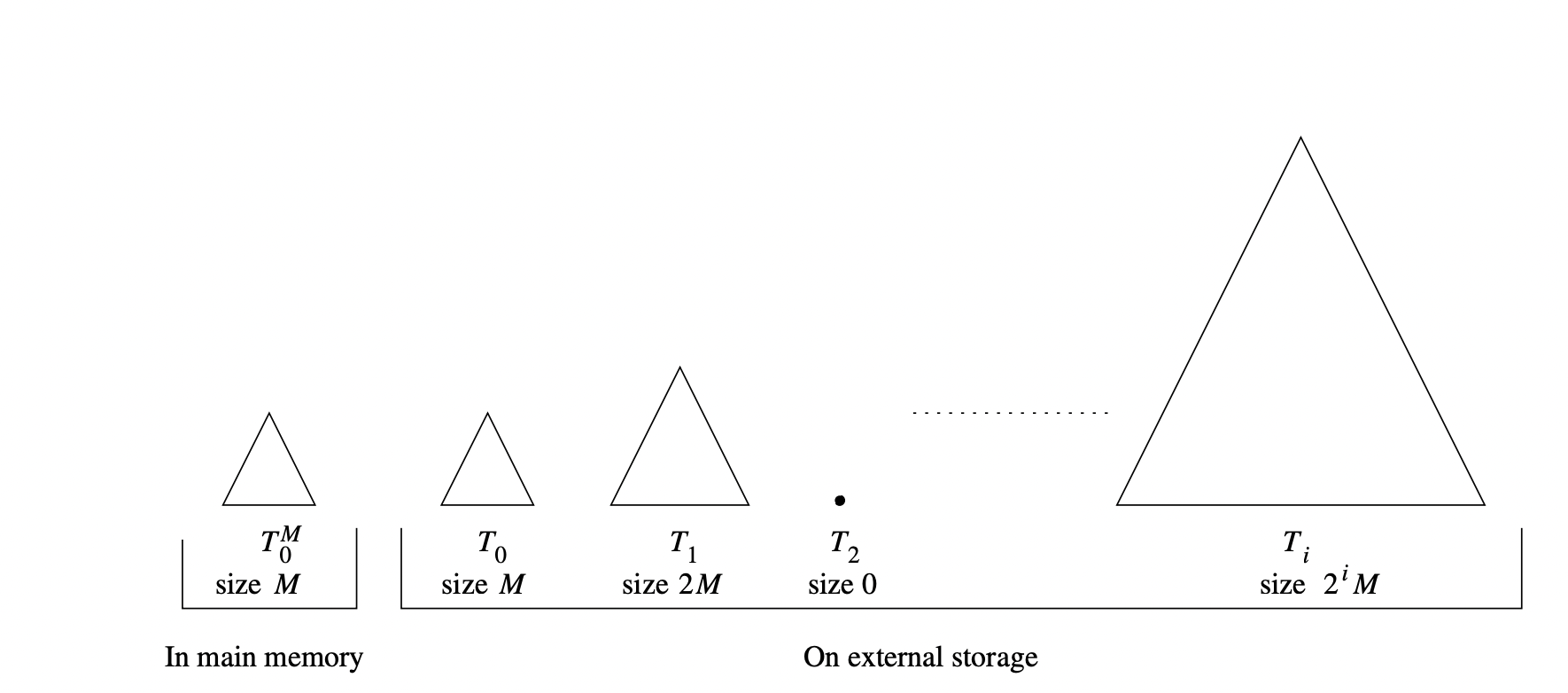
bkd树实际上不是一颗树,而是很多树组成的森林,
如下图所示,第一课树在内存中(当然在磁盘上也有备份)剩下的树在磁盘上存储,T(i)的空间大小是T(i-1)空间的两倍,按照两倍的关系指数递增。
当T(0)到T(i-1)的树都满之后,继续插入,就会将T(0)到T(i-1)的所有的数据全部全部移动到T(i),类似将二维游戏2048转换为一维的场景
优点
- 在森林中越大的树越靠后更新的频率越低
- 前面的树都满了后才会将前面的数据全部移入新的树中,并且空间大小刚好,空间利用率高
缺点
每次查询时需要查询所有的树,但是因为树的容量是指数级增长的,因此树的数量可控,查询开销可控
参考文档
B+ tree – Wikipedia
B+ Tree Visualization
https://cloud.tencent.com/developer/article/1366835
https://blog.csdn.net/waltonhuang/article/details/106694326
https://zhuanlan.zhihu.com/p/88005015